
So you turned on Amazon GuardDuty, and you got your first findings. You’ve seen your first brute force attack coming in. Maybe you’ve witnessed some attacks on your Identity and Access Management (IAM) Application Program Interface (API), or discovered some Bitcoin activity on your Virtual Private Cloud (VPC) that shouldn’t be there.
That’s a great first step you just took. A sound security monitoring practice starts with threat awareness. If this is your first encounter with intrusion monitoring, you might be surprised at the amount of threat activity discovered — it’s not just happening to others. Two words now come to mind: Now what?
Incident Response Challenges in AWS Environments
Effective incident response can be challenging, for anyone. Do you look at every individual incident immediately? How do you assess the confidence level of the finding? Can you act on your own, or do you need partners in your organization to provide a meaningful response? What really happened to begin with?
To make things worse, in an AWS environment, there are some very specific challenges to deal with. You need both expertise in security and AWS architecture to understand the threat, and assess your response options. Moreover, assets can appear and disappear dynamically, and some identifiers of assets that are pretty stable in a traditional IT environment (such as IP address) are less reliable due to their transient behavior AWS environments; many traditional security solutions have a hard time dealing with that kind of setup.
But there’s also some good news:
- AWS provides data (such as the CloudTrail API logs) that makes it possible to build real-time model of your AWS assets and environment. Maintaining an accurate and up to date view of your assets is the biggest problem in implementing detection and response practices in traditional IT environments. That problem is solved in AWS — as long as you take advantage of it.
- AWS also offers more automation capabilities to help you with response actions, like quickly quarantining a host.
- Environments that are built for scalability offer you the option to quickly terminate and replace a compromised host (instance in AWS) if you determine that it has been breached. This is an easy and big win.
What’s the way forward? Work the problem, one step at a time. Let’s break it down.

Alert Logic MDR Essentials Provides Necessary Context
The trick with incident management is to stay focused on these three questions (above) in sequence. Don’t skip steps. Don’t stop somewhere in the middle. Work the problem.
Alert Logic has been singularly-focused on incident and exposure management since its founding, and has been investing in sound AWS Security practices many years. With MDR Essentials, we’ve bundled all our expertise and technology to create an affordable and scalable solution to help you with these steps. Let’s have a look.
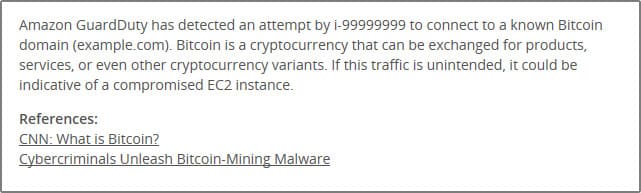
- Assess what happened: We’ll give you a sound, down-to-earth explanation of the behavior that was detected to start. Additional pointers to more resources for extra context are added when appropriate. Here’s an example for a Bitcoin finding.

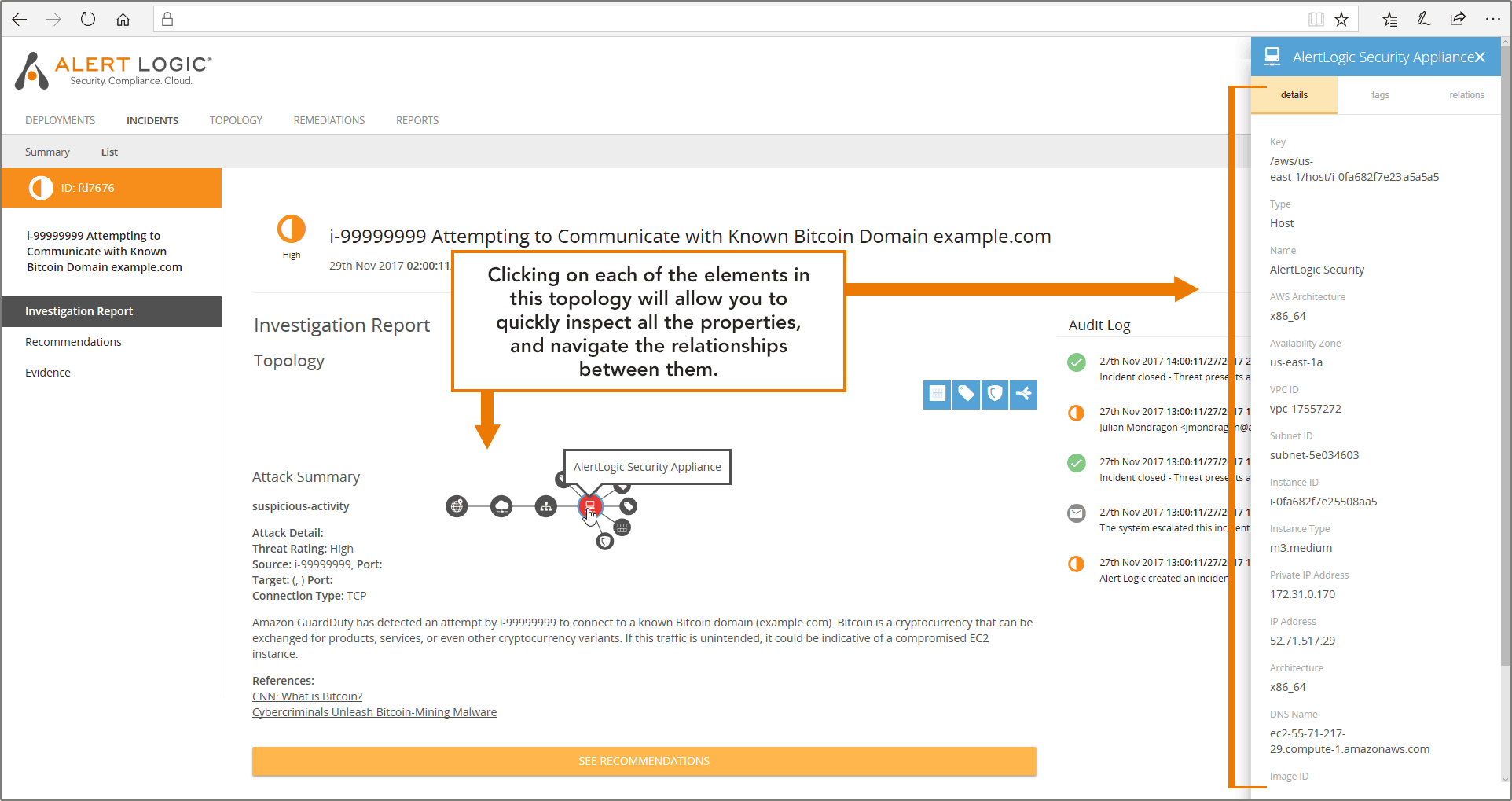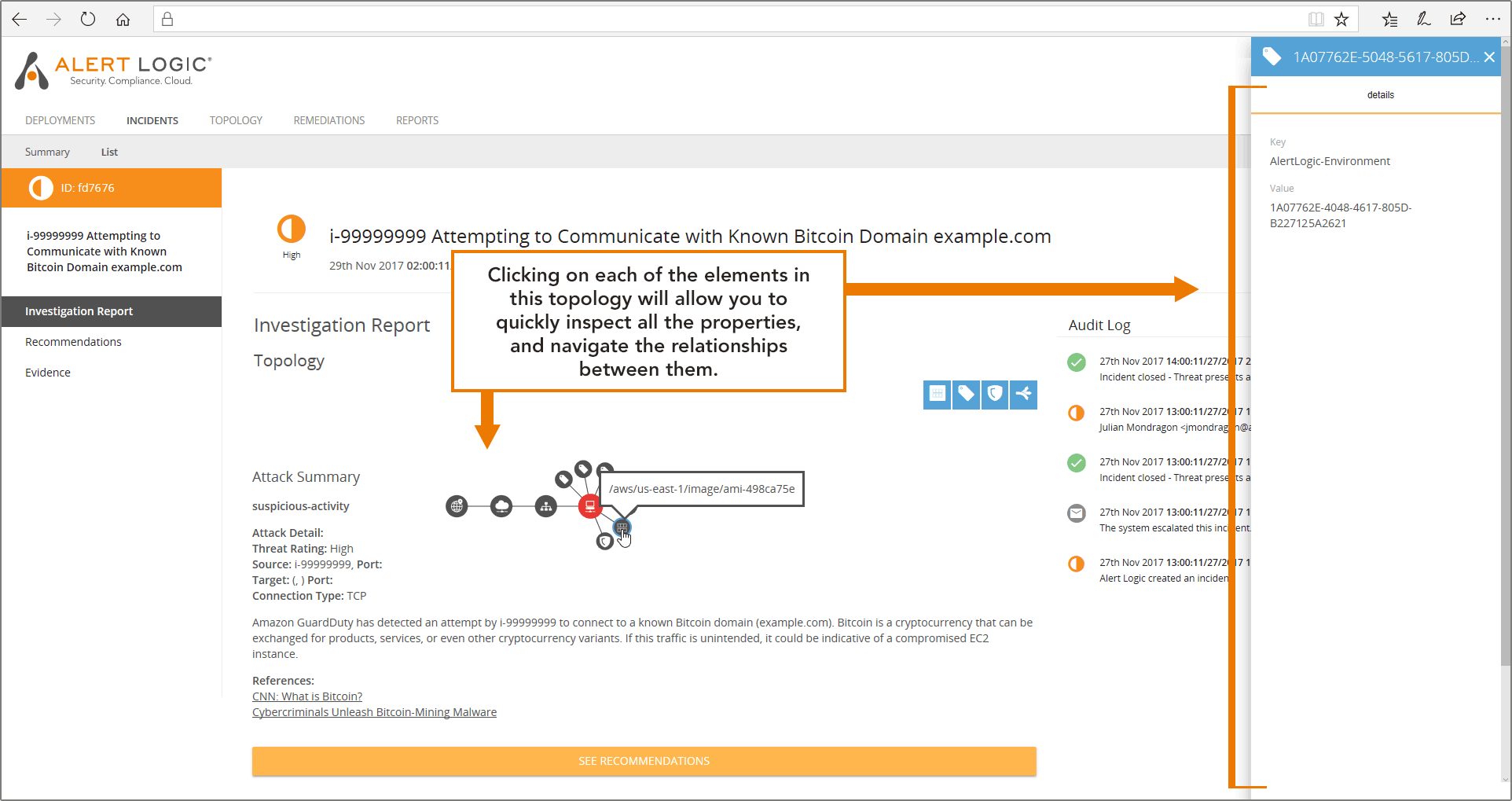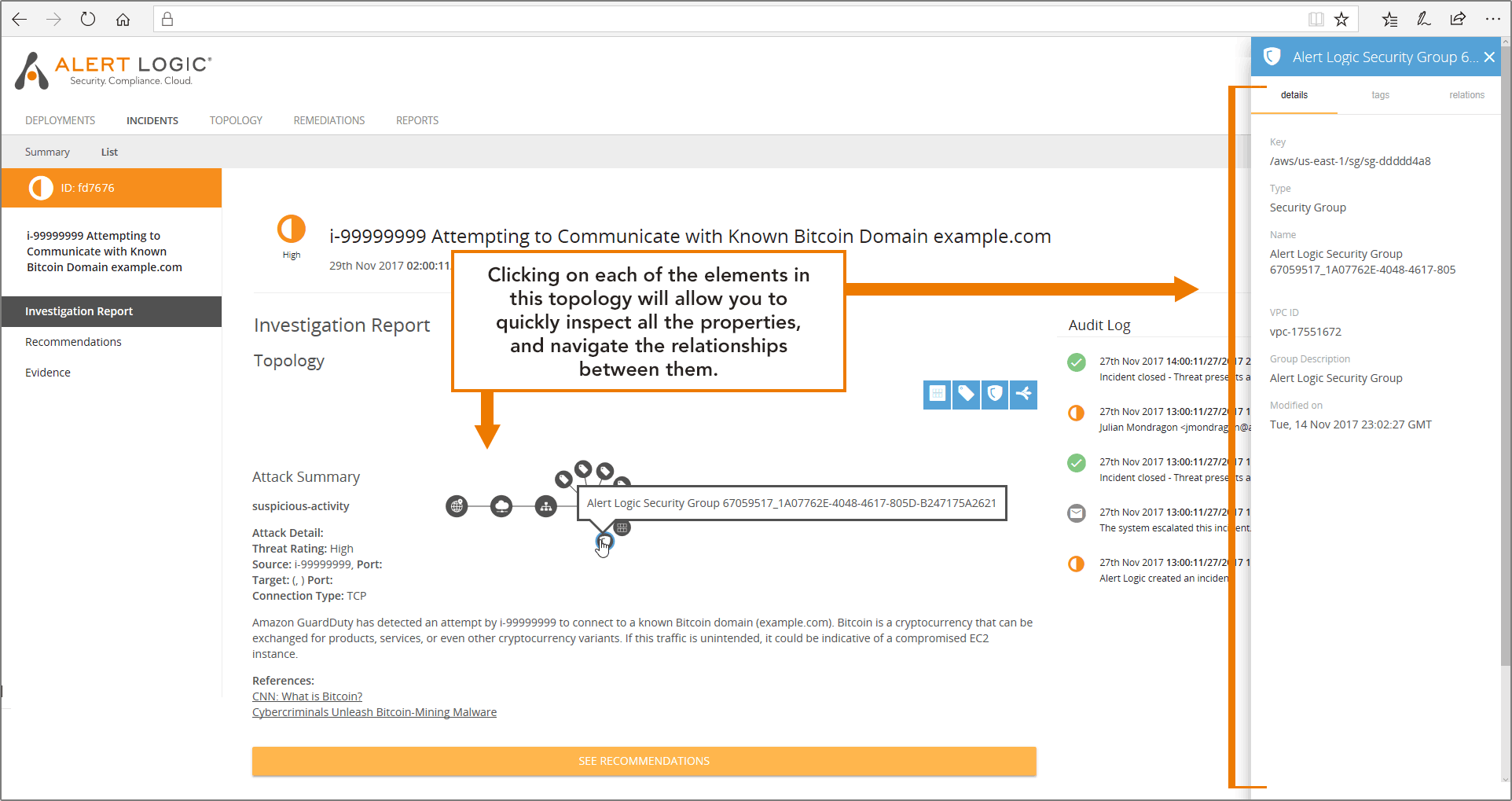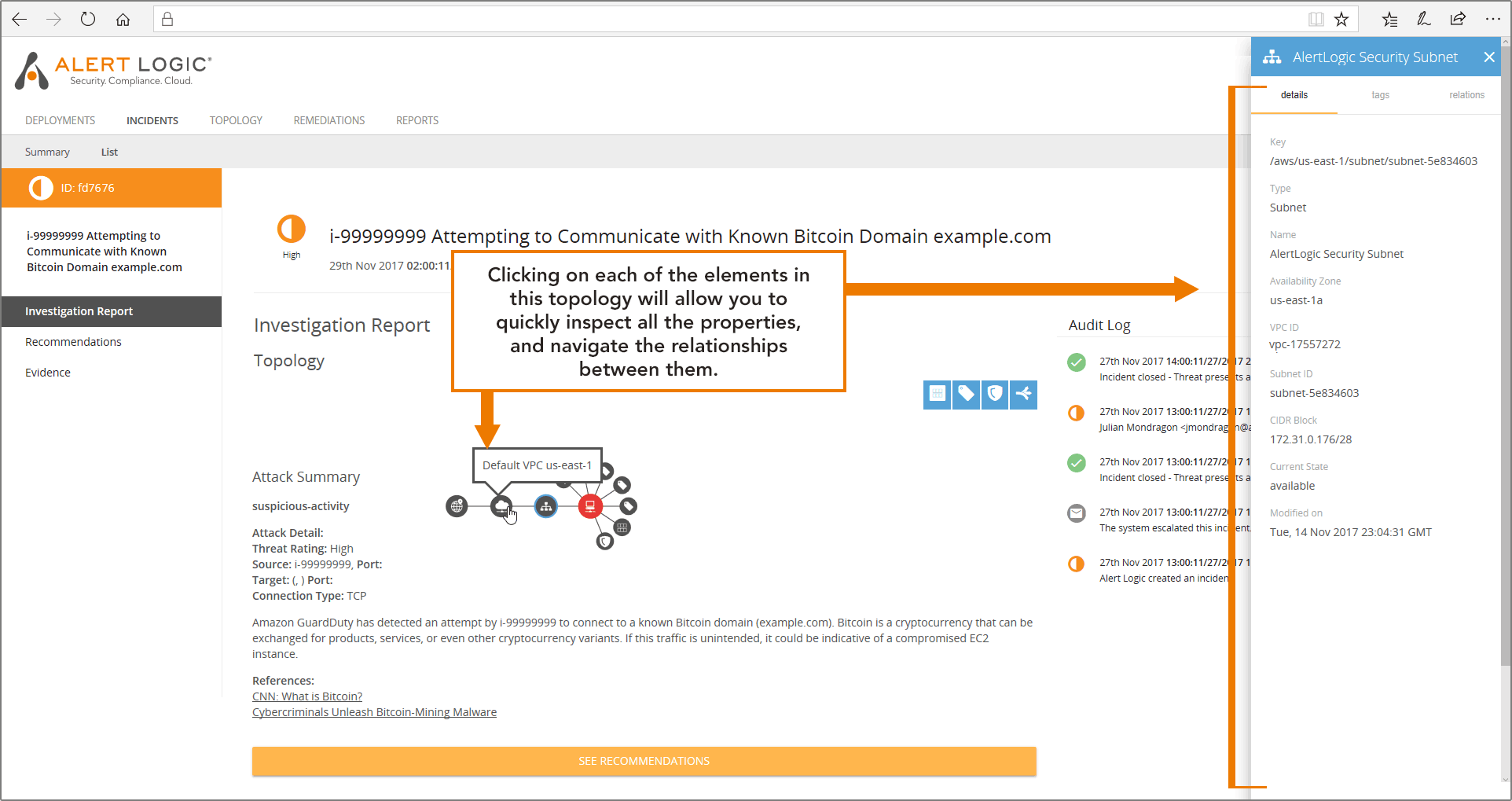
- Understand what asset is involved, and where is it situated in your environment: MDR Essentials constantly updates the information it has about all your assets by subscribing to CloudTrail API updates for your account. That means that when we pick up a GuardDuty finding, we can start with the information that Amazon GuardDuty provides, and build on that to create a topology view around the asset being attacked. In the case of an incident involving an EC2 instance, you’ll get a graphical representation of the instance, its tags, its security groups, its auto-scaling-groups, and attached subnet, VPC and region.Let’s illustrate again what this looks like with our Bitcoin incident. We see the host (in red) and we see it has tags, the AMI it is running off of, and there’s a security group applied to it. We also see it’s part of a subnet, in a VPC of a region.
 The net of it is you’ll get a good grip on what is being attacked and what is adjacent to it. This is going to help you with your next actions, when we start pivoting from understanding to response.
The net of it is you’ll get a good grip on what is being attacked and what is adjacent to it. This is going to help you with your next actions, when we start pivoting from understanding to response.
 The net of it is you’ll get a good grip on what is being attacked and what is adjacent to it. This is going to help you with your next actions, when we start pivoting from understanding to response.
The net of it is you’ll get a good grip on what is being attacked and what is adjacent to it. This is going to help you with your next actions, when we start pivoting from understanding to response.[Related Reading: Create a Comprehensive Automated Incident Response Plan Before You Need It]
Short-term Actions
Next are the short-term action recommendations. You basically have two objectives in this phase: Validate and confirm the detection, and containment [Stop-the-bleeding!]. The objective here is to stop the attack in its tracks or contain further spread.
We will provide suggestions for these actions, and provide references to knowledge base articles or the relevant AWS resource that can help you here. Some typical examples will be to cut off the attacker’s network access using your security group, quarantine the instance, and/or validate if malicious software is present on the instance. Sometimes we’ll suggest to just kill the instance, which you may do if you know the application was built to scale up automatically.
Clearly, this phase requires you to be aware of your environment, and your company guidelines and policies. You might need to cooperate with application or operational owners of these assets to agree on the best course of action for you.
Last, but not least, you will typically start getting an initial, or even a final idea of a more structural fix. It’s ok to track that already (we provide the ability to update notes in our incident workflow, even before you close the incident out), but don’t rush into executing that yet. Consider coming back to that and reflecting a bit more, consulting maybe with some of your peers after the rush of containment.
Here is an example of some short-term recommended tactical actions you should expect.

Making Things Better
Once incidents are contained, you can finally take a breath. Now is the time to go back to your ideas on improvements. Where short-term actions were all about containing the current incident on your current asset, structural actions are about getting better. You take a little bit of time, you expand on your short-term analysis, and start looking at how you can prevent this from happening again, for this asset, and/or for other assets. In security speak, you are now pivoting from incident management to exposure management.
The underlying root-causes for incidents are almost always an exposure of some kind (which means typically either a configuration issue or a software vulnerability on your instance). Therefore, structural actions are about how to reduce that exposure. And, while you’re at it, think a little bit out of the box. The incident was about one specific instance, or subnet, but what about the others. Do you think they have similar issues? Take some time to gather your thoughts, confer with peers or your team lead, and come up with suggestions. This is the part where you make the biggest impact on the security of your environment.
In Alert Logic MDR Essentials — as part of your subscription — you get access to a whole range of proactive configuration checks for AWS best practices on your infrastructure to jump-start your exposure analysis. We don’t just wait for incidents to happen; we actually provide you with a bunch of pre-built configuration checks based on AWS best practices that you can consult. As the user, you don’t need to wait for an incident to happen to start acting on those suggestions — an ounce of prevention is worth a pound of cure.
But we also know it’s not always easy to stay on top of all these exposures, and right now, you’re looking for a suggestion about how to make things better in the context of this incident.
This is where our investments in understanding your asset’s context for this incident, and our pre-built checks that are already running will start to pay off. As part of our suggestions for structural improvements, we will take the asset information and its surroundings (security groups, subnets, VPCs, etc), and go validate if we know of any exposures these have that could have contributed to the incident. Through a simple link, you’ll be able to inspect these, and either improve on them immediately (if you can do it yourself), or put them in a prioritized remediation plan that you can execute on at your own pace, with your operational partners in the organization.
This whole exposure management process is what will incrementally start making you more secure if you diligently look at them when you work on your structural actions for an incident. There’s a ton more functionality there we’ll discuss in another blog, to help you prioritize your exposure management and optimize your workflow–stay tuned for that.
Here again is the example for this Bitcoin incident:

The last bullet here shows we found weakness in the security group that is protecting this asset. Let’s click on that link, and see what is suggested:
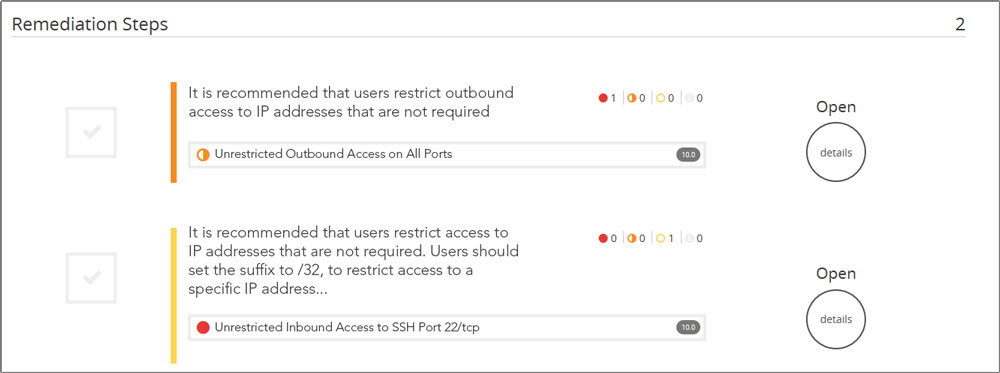
We are brought to the remediation section of the portal, where we see two weaknesses in that security group. The first one here is of particular interest–the security group allows unlimited outbound access, a default for security groups. We tend to think of inbound access restrictions as the key control we can apply, but outbound access can be pretty effective too. A lot of harmful software that gets on hosts is completely dependent on being able to access the internet to be effective, through calling home, or accessing resources. This is true for Bitcoin mining as well. While not a panacea, it would be a good idea to start listing what outgoing access is really needed from this host, or even subnet, or even VPC. Usually, server-side resources only need a pretty restricted set of outbound services to function normally. You could try to start listing those, and implement configuration or automation on your security groups to only allow these ports and destinations. That will seriously cripple not just Bitcoin clients, but a whole host of Trojan and malware variants relying on outbound access, and make containment of future incidents a whole lot easier.
MDR Essentials can help with that actual fixing as well; when you decide you want to execute on this, you can mark the remediation as fixed, and we will confirm the fix. If it’s fixed, you’ll never see that remediation again, but if it isn’t, we’ll re-open it for you and keep the nagging going. You of course might decide to do something else instead and dispose of our remediation–that is totally up to you.
With our help, or based on some of your own thinking, this last step, when done incrementally over time, is going to pay dividends in bringing down your overall exposure levels, and ultimately make your environment more secure.
Incident Response with MDR Essentials
Let’s go back to those 3 things and see how we try to help

Here’s your recipe for handling incidents:
- Try to understand what was detected
- Get situated on the asset – what is it, where is it, who’s responsible for it?
- Now take your short-term actions – confirm the detection. If confirmed, contain the incident. Note down your initial root-cause analysis for your next step. You’re now ready to close the incident, and pivot to addressing the root-cause
- Take a breather and consider the improvements you’d like to make.
- Can you do it yourself, are empowered to do it, and it is an easy fix? Do it now.
- Does it take more time, involve more risk, and/or require you to get approval or work with other teams? Put it in your remediation plan, and track your plan, working with your partners in the organization.
Thoughts from Cloud Security Experts
“That sounds great, but I am totally not ready for this yet, and I’m understaffed.” This is something we see and hear from our customers every day. It still requires skill and expertise, and, you know, you also have a day job.
Here’s some ways forward if you still feel overwhelmed:
- Start with some incidents, and just review regularly. There is a middle ground between looking at every incident and doing nothing. You should start by regularly reviewing what comes through, and get a sense of what is hitting you. MDR Essentials offers a daily digest report of what we found. You could look at that, and see what is happening most. Then go to the GUI and pick one of those to evaluate. Set yourself a goal of looking at the top occurring incident, for that day. Then, two. Then, three. Consider which remediations suggested would work well for your organization. Is there one where you feel there is a lot of bang for the buck in terms of improvements? Try to get that one done.
- Create awareness with your peers and management. Talk to your peers and managers about what you’re finding, about the exposures you should be reducing. Use some of the other reports to create more awareness. Our experience is that incidents can be powerful teachable lessons that illustrate the need to resource an incident management and exposure practice. Security can sound abstract until you can show that it happens to you. Like – all the time. See what happens.
- Get help. Alert Logic, as well as other providers offer additional services where we can help you with these processes, where Security Operations Center analysts will support you in this process, and take a load off your daily work. Consider some of the options, and think it through.
The key is to get started on the journey, today. There is no sticking your head in the sand. This stuff is happening. Amazon GuardDuty gives you visibility on it, Alert Logic can help you make sense of it. To learn more, visit the Alert Logic MDR Essentials page, or schedule a demo to see first-hand how it could benefit your organization.